
By Matt Stahl, P.E.
Artificial intelligence will transform utility asset management, helping even the most complex infrastructure cases.
Every day, utility managers grapple with unexpected infrastructure failures in pipe networks and other systems. While they can pinpoint a few problem sources and trends, their supporting data are often inconsistent, and repair patterns suggest complex drivers.
And because these managers usually lack funds to hire additional staff or obtain adequate tools to understand these concerns, they often find their time is monopolized by reacting to put out fires rather than proactively addressing root issues. However, the advancement of artificial intelligence is revolutionizing asset management and helping address chronic, costly, and dangerous infrastructure problems.
Asset management defined
Asset management is an operational framework that emphasizes a proactive approach to prioritization and maintenance of utility infrastructure, including pipes, access points, pumps, and other horizontal or vertical components of utility systems. The benefits of this framework include risk mitigation, safer working environments, higher levels of customer service, optimized efficiency, and extended life of utility infrastructure.
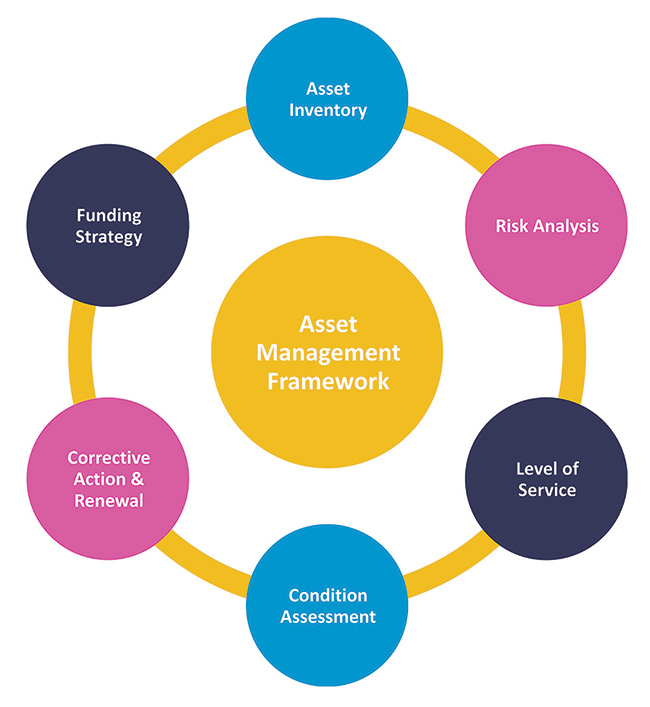
Momentum is growing among utility owners to embrace and implement asset management philosophies. However, a major challenge owners face with standard asset management is effectively understanding and using the valuable information that’s available from different utility systems.
This is where AI comes in.
AI can help engineers better understand asset management in many ways, primarily by more easily recognizing the factors at play: asset deterioration, maintenance patterns, operational cycles, the remaining useful life of assets, and data gaps for infrastructure systems.
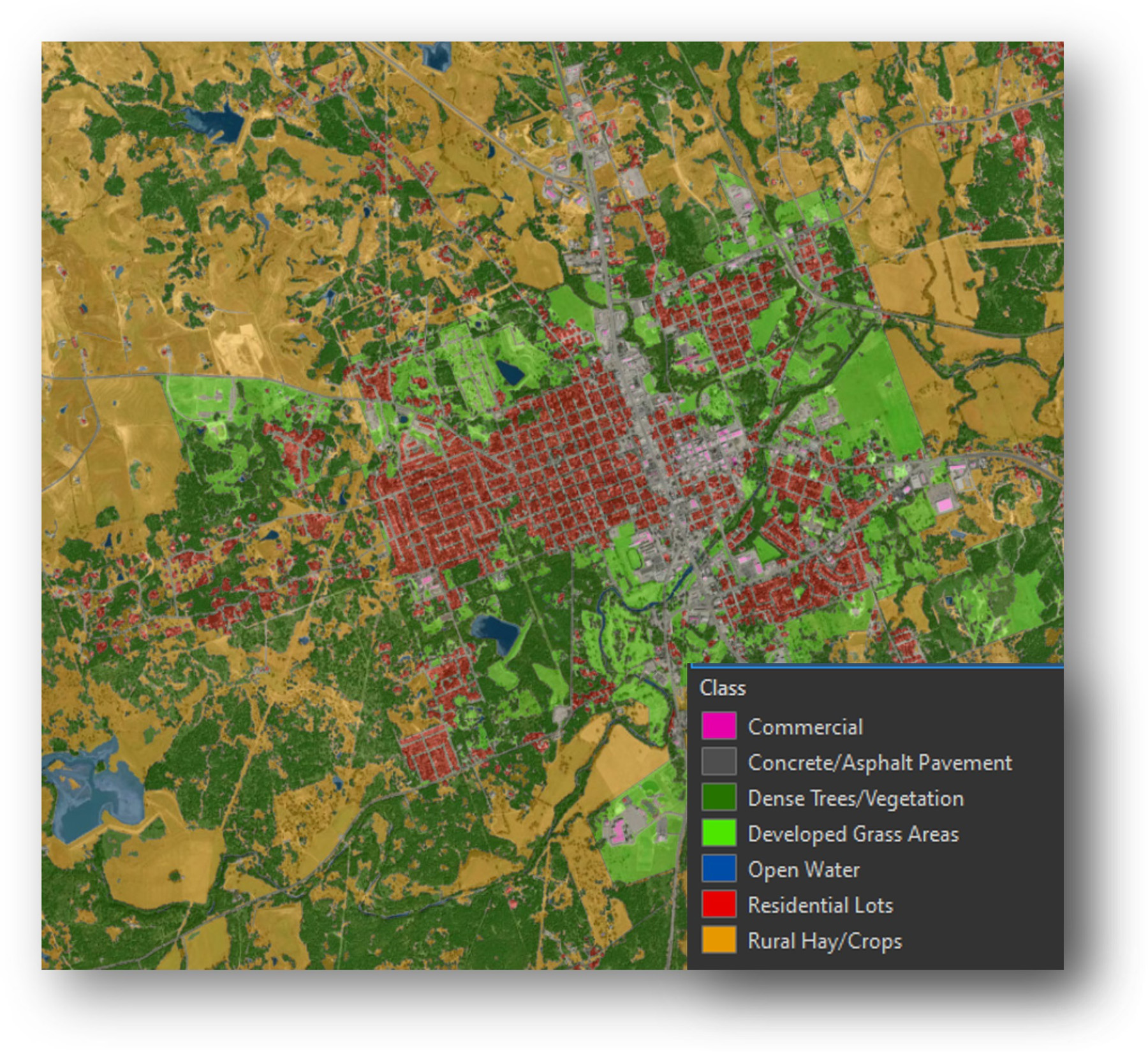
A variety of AI tools and techniques can help civil engineers make better infrastructure decisions. Computer vision, an AI technology that recognizes objects in images and videos, can process “unstructured” data (such as photos and videos of utility facilities) to produce “structured” or ordered, tabular data outputs that enhance decision support for asset inventories and condition assessment. Geospatial AI, which refers to AI-based tools and processes that work with location-based data, can help utilities create better geographic information system, or GIS, datasets and models to understand how physical processes, such as erosion, subsidence, impervious cover, and soil moisture change over time. Machine learning, the application of AI algorithms to learn from datasets and make predictions, provides insights as to how and why assets deteriorate and how to prevent failure.
In contrast to traditional asset management, AI-augmented asset management enables learning from large and historical datasets. Engineers and utility leaders are limited in the number of factors they can reasonably evaluate at one time. For example, when working to mitigate utility failure or while prioritizing capital projects, evaluators might consider 5 to 10 primary driving factors. Although most problems likely have only a few main drivers, secondary factors can be multiple and varied, and their contribution may be crucial to forecasting a correct outcome.
With today’s computing power, machine learning can model problems with multiple drivers or factors more effectively, specifically, and consistently than humans. Models establish and weigh what is important and minimize what is not to make better predictions. Machine learning models, therefore, empower utility managers and engineers with new and actionable data-driven insights.
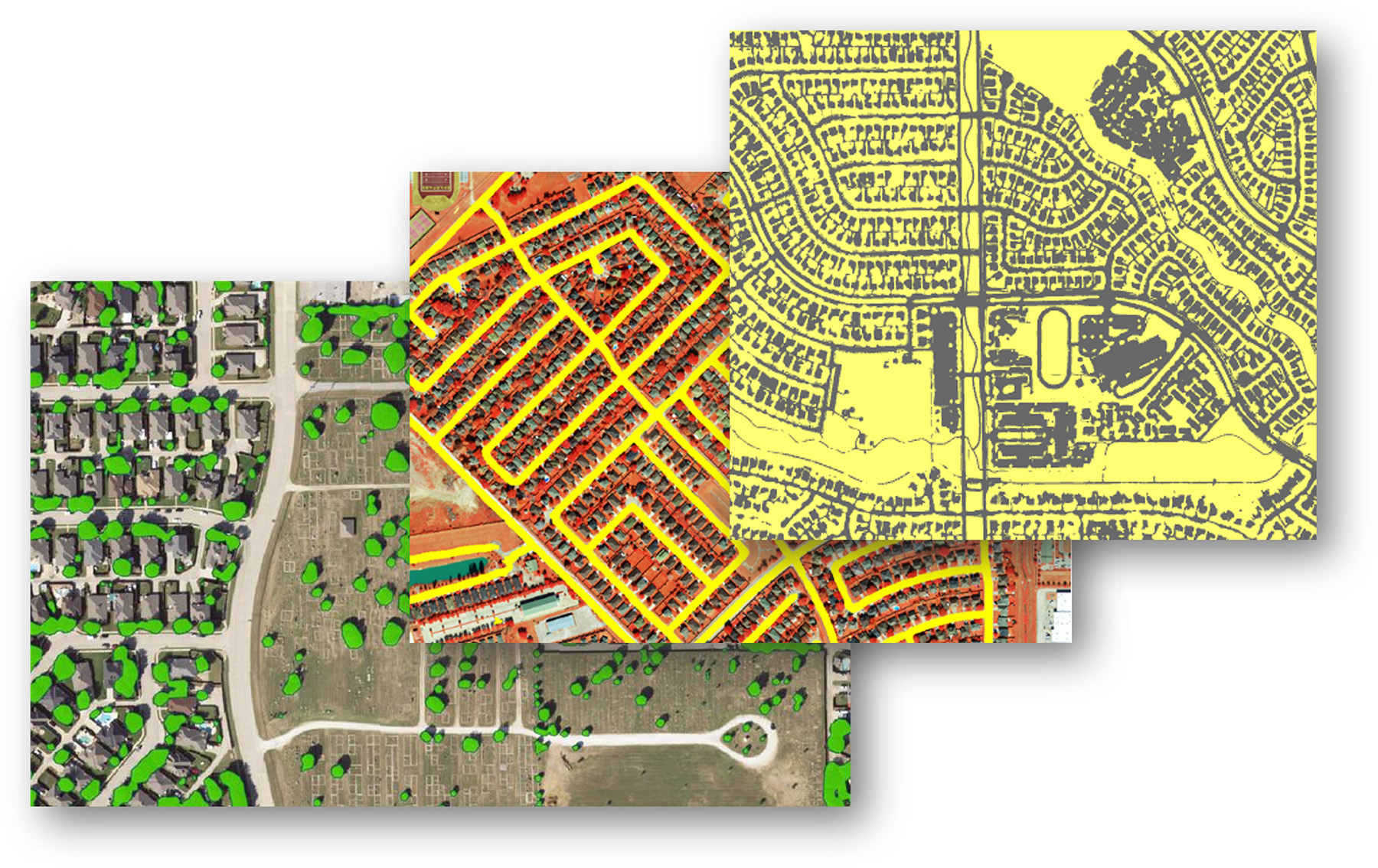
Large datasets created over extended time periods are better suited for most AI applications. However, smaller utilities with complete datasets (e.g., digital records on multiple attributes, work order system information, five-plus years of historical and geolocated data) can also be good candidates for AI-augmented asset management.
AI 'languages
Learning how to work with code-based AI models is like traveling to a foreign country. While it is possible to visit without speaking the native language, meaningful work requires learning that language or hiring an interpreter. For AI models, the “native language” is typically Python or R — both general-purpose programming languages. Engineers with computer coding experience can start quickly with open-source AI tools and libraries.
For those new to coding, consulting firms that specialize in AI for civil engineering — like Halff, a full-service infrastructure consulting firm — are available to guide the AI-integration process. Additionally, no-code or low-code tools, such as those available in GIS, are constantly improved to simplify AI implementation. These tools encourage exploration and testing of questions and persistent problems in situations in which AI may add value, and they make AI more accessible.
Advanced degrees are not required to successfully apply AI to real-world problems. Excellent learning resources are freely available in books and online. Like other technical disciplines, AI is best learned through a comprehensive and structured framework. Certificate programs through academic institutions offer a cost-effective alternative for understanding data science or machine learning.
Engineers who work in asset management know that it can be difficult to separate the philosophy of asset management from the supporting software applications on the market. Likewise, AI should be distinguished from the growing number of software platforms that integrate AI components. Comparable to building information modeling or 3D-modeling technologies that have been adopted in recent years by civil engineers, AI tools typically involve a learning curve and require training for effective use.
Understanding the AI spectrum
“Using AI” can mean many things, from employing large-language-model chatbots to writing machine learning model code. AI models and tools cover a broad spectrum.
In May, a national conference panel at the Society of American Military Engineers’ Joint Engineer Training Conference & Expo discussed the AI spectrum: general versus narrow, unsupervised versus supervised, and generative versus discriminative. General AI models mainly “learn” in an unsupervised fashion (data are not pre-labeled or tagged), and some — known as generative models — create new content. General models can play chess and fly jets, and they are designed to mimic human-like decision-making capabilities.
On the other hand, narrow AI models typically learn about specific problems in a supervised fashion (from pre-labeled data) and produce outputs that classify or identify the information of interest, making them discriminative models. Narrow AI models identify objects in photos or videos, classify aerial imagery, and predict future events and important outcomes.
Choosing the right type of AI model and the data that are required depends on the engineer’s or utility’s end goal. When considering AI tools to support decision-making, first evaluate the project’s needs.
Key considerations for an AI-needs evaluation include:
- What solutions have already been attempted?
- What data are available to support AI?
- What are the perceived benefits of an AI-based solution?
- How much money, time, or other valuable resources will the AI solution potentially save?
Thinking through these considerations will improve a utility’s experience as it seeks to work with AI. Though it can be a useful tool under the right circumstances, AI is not always the best tool for the job. From a business perspective, when any AI solution is proposed, other solutions and methodologies should always be reviewed and evaluated.
Under a 2020 strategic initiative to advance data analysis and AI, Halff devoted resources and staff to investigating AI models and tools for different practice areas, determining how to apply narrow AI models, evaluating the current and future needs of utility clients, and identifying opportunities for improvement in services and decision-making with the addition of AI tools. The firm’s AI integration is ongoing, and its engineers and computer scientists are applying tools that add value to both discriminative and generative AI applications.
Achieving goals
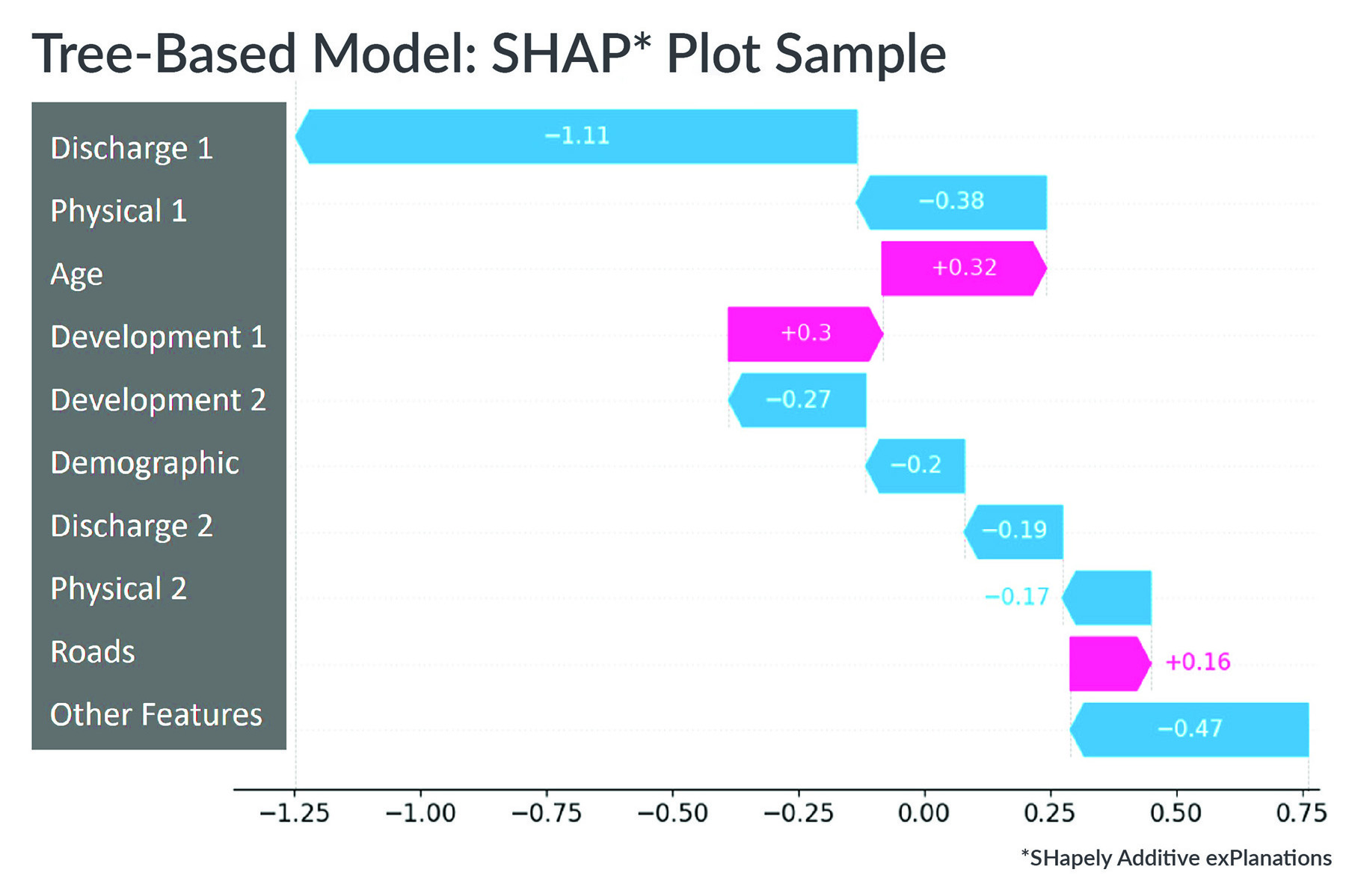
Halff has provided machine learning services for the city of Fort Worth, Texas, for its Storm Drain Rehabilitation Program project since 2023. The city used Halff’s in-house machine learning platform called Smart Likelihood of Failure, or Smart LOF, along with an approach called SHapley Additive exPlanations, or SHAP, to analyze the platform’s output. The tool improved the city’s storm drain maintenance prioritization by training the AI model to forecast pipe conditions using historical data. A 2022 pilot model delivered 80% or better “true positive” results.
Because of this strong match between model predictions and field results, the city has applied the Smart LOF model for 2023-2025 as part of its award-winning storm drain rehabilitation program. The Smart LOF model results will provide Fort Worth program managers more accurate and detailed information on the state of the approximately 40 mi of storm drains the city inspects and evaluates every year.
Other measurable benefits of the model were a 30% increase in model performance compared to non-AI, risk-based methods. The AI system also delivered more consistent evaluations of assets’ likelihood of failure because it relied on a more comprehensive set of related factors.
The application of a machine learning model was not without challenges. Three issues the utility overcame were post-processing raw CCTV data that the city used to monitor the storm drains, converting non-numeric data, and selecting the correct failure threshold for high-impact decision support.
As a separate effort, Halff applied a deep learning AI model to improve quality assurance and quality control in detecting defects in Fort Worth’s storm drains. Halff first offered this AI service in 2021 as part of the city’s Storm Drain Rehabilitation Program.
Challenges of the QA/QC model used to identify the defects included extensive, manual data labeling and the reality that some consequential pipe defects (collapsed pipes, void risks, etc.) are less common, making these defects more difficult to represent in the training data. CCTV quality and format also varied by vendor.
Measurable benefits of using AI to enhance quality control included:
- 85% or better true positive identification of defects.
- 50–60% savings compared to a manual CCTV video QA/QC.
- Risk mitigation of QA/QC on all new inspection datasets.
In another endeavor during fiscal year 2024, Halff prepared a master drainage plan for 65 areas of high flood risk, or “damage centers,” for the San Antonio River Authority in South Central Texas. Halff used lidar and range scanning of residential structures to develop, train, and test a machine learning AI model that forecasted planning-level finished floor elevations for structures. The project helped establish the flood risk from multiple storm events, which helped planners prioritize and develop capital improvements for flood mitigation or use nonstructural alternatives.
The challenges of the machine learning FFE model included the need to extract training data from point clouds, a lower performance level for large lots, and the need to identify and resolve FFE outliers (3-5% of output).
Measurable benefits included:
- Rapid FFE extraction for more than 11,000 structures.
- 90% cost savings over traditional surveys using terrestrial scanning with machine learning modeling.
Framing the AI question
To achieve return on an AI investment as quickly as possible, it is important to start by framing the question.
To produce a clear and concise problem statement for the successful application of AI models, consider key problems and questions that need answers, how to frame questions, and whether an alternative, simpler, more cost-effective method that does not involve AI might provide an acceptable solution.
A binary classification model might be a good fit if the question has a yes-or-no answer. If the response requires a category or a label, a multiclass classification model can be suitable. If the question generates a numeric response, a machine-learning regression model is likely appropriate.
After framing the question, determine what data are available to teach a machine to learn the right answer. This defines the target or dependent variable, which can depend on many factors: What volume of data is there to train a model on the target variable? What is the time span of historical information? How complete is the spatial distribution of the data? Does the dataset represent the overall group or area of study?
Using the example of flood prediction, consider whether the data reflect the range of cases for flooding — urban and rural, developed and undeveloped, and variation in the study area. Is any group in the cohort over- or underrepresented, or is bias present?
Next, consider the many factors that influence the target variable; these are the predictor or independent variables. What physical, social, spatial, and temporal variables might be involved? There are often a dozen or so, but possibly many more, independent variables involved in fully describing any problem or question.
Data limitations are common, so what surrogate data variables might be used? Do the available data adequately describe the problem? Or are more data needed?
AI models attempt to distinguish the most important factors that influence a problem or question, so a good practice is to start broad and later focus, iterate, and refine the model by evaluating the results and the appropriate model metrics.
AI recommendations for utilities
Aspiring AI practitioners can play an important role in shaping the future. The following insights from Halff’s AI experience may be useful for utilities:
- Data readiness is crucial. Many datasets are not suitable for AI, and some utilities may not be ready to apply AI because they do not have enough digital data or the right data to support a meaningful application of the tools. If this describes your utility, closely examine your data needs and gaps. Next, make a plan and take steps to collect high-quality, high-impact data that can be successfully used for AI analyses going forward.
- Data preparation is required. Data prep is generally the most time-consuming step in AI modeling. Engineers working their way up the AI learning curve will undoubtedly come across the 90/10 rule: 90% of AI application time is pre-processing, while 10% is modeling. Awareness of this norm is valuable when developing the scope of an AI project.
- AI models have limitations. AI models are touted as being “smart,” but in some ways, they are rather gullible. A model’s performance is closely tied to the quality (consistency, label and scoring accuracy, format) of the input data. A model can only learn from the data provided. Start by using a basic model, perhaps a generalized linear model like logistic regression, to determine if a dataset has potential. If its performance is acceptable, then try a more advanced model, such as a nonlinear random forest or decision-tree model. Meaningful and strong predictive results are more dependent on the quality of the dataset and the predictor variables than on a particular AI algorithm.
- There is strong potential in the following takeaways that can help engineers use AI tools more effectively in their communities:
- Power of time series data. Time series modeling will become more important as AI practitioners advance their use of AI to include the additional dimension of time, and the implementation of robust work-order management systems will enable the use of historical data in AI models. AI models with a time component will offer new insights and enhance decision support.
- Gridded data benefits. Gridded/raster datasets, or pixel-based images with unique (numeric) color and tonal information in each pixel that creates the image, will help AI models evaluate multiple spatial factors quickly and efficiently. Location-specific attributes can lend insights to the assets and systems that engineers manage. Gridded formats can be used to represent spatial data in ways that can be leveraged to improve AI model outcomes.
- Model explainability. Tree-based models implement a series of yes-or-no decisions for AI classification and prediction tasks, using a branching node framework to evaluate factors that contribute to a correct prediction. These and other “explainable” AI models can offer better transparency and communicate clear results and drivers to utility stakeholders. Tree-based models can approach the performance of neural networks (AI models with a structure that mimics human neurons) while avoiding the complexity and run times of those models.
- AI strategy. A needs evaluation is a process that will benefit every utility considering AI integration. The evaluation should involve a straightforward dialogue about current and future infrastructure management challenges, current processes and outcomes, data availability and AI-related data needs, and possible AI resources. Evaluating AI needs and options today will help utilities formalize a data strategy that can advance solutions tomorrow.
Artificial intelligence can greatly strengthen a utility’s asset management. AI is not just about deploying cutting-edge models; it is about harnessing the power of data to bridge the knowledge gaps that have long existed in utility asset management.
Continued AI development empowers engineers and utility owners with the tools to better address reactive repairs and proactively engage in predictive maintenance. Utilities can effectively leverage their data, optimize maintenance schedules, predict potential problems, and streamline the operation of critical infrastructure.
As utilities shift toward optimal data usage, AI’s innovative tools will help engineers and utility owners secure a more collaborative and reliable future for our communities.
Matt Stahl, P.E., is the AI/infrastructure management team leader at Halff in Fort Worth, Texas.
This article first appeared in the November/December 2024 issue of Civil Engineering as “The Future of AI in Asset Management.”
